
はじめに
パナソニックプログラミングコンテスト(AtCoder Beginner Contest 186) – AtCoder
A,B,C,Dの4完でした。
Eが数学的な知識が増える回で楽しかったです。
A – Brick
Nキロまで載せられるトラックに、Wキロのレンガは幾つ乗せられるかを求める問題。
a*W<=N a<=N/W
を満たすような最大の整数aが答えです。
N/Wの答えは小数になることもありますが、整数aはN/W以下であるため切り捨てる必要があります。
#include<bits/stdc++.h>
#include<atcoder/all>
using namespace std;
using namespace atcoder;
int main(){
int N,W;
cin>>N>>W;
cout<<N/W<<endl;
}
B – Blocks on Grid
B – Blocks on Grid (atcoder.jp)
ブロックは増やせず、減らすことしかできません。
そのため、同じ個数にするブロックは0以上Amin以下となります。
また、同じ個数にするブロックは大きければ大きいほどいい(取り除くブロック数が少なくなる)ため、Aminに揃えるのが最適だと言えます。
#include<bits/stdc++.h>
#include<atcoder/all>
using namespace std;
using namespace atcoder;
int main(){
int H,W;
cin>>H>>W;
int Amin=INT_MAX;
int Asum=0;
for(int i=0;i<H;i++){
for(int j=0;j<W;j++){
int A;
cin>>A;
Amin=min(Amin,A);
Asum+=A;
}
}
cout<<Asum-Amin*(H*W)<<endl;
}
C – Unlucky 7
Nの最大が10^5と弱めです。
log10^5(底は8)でも、5.xxxくらいなため10進変換、8進変換、それぞれの桁から7を探すを愚直にやっても最大20回程度の計算で終わります。
10^5回、20回の計算をしても余裕で間に合うため愚直で大丈夫そうです。
#include<bits/stdc++.h>
#include<atcoder/all>
using namespace std;
using namespace atcoder;
int main(){
int N;
cin>>N;
int ans=0;
for(int i=1;i<=N;i++){
bool f=true;
bool f2=true;
int n=i;
while(n!=0){
if(n%10==7) f=false;
n/=10;
}
n=i;
while(n!=0){
if(n%8==7) f=false;
n/=8;
}
if(f&&f2) ans++;
}
cout<<ans<<endl;
}
CPUの処理速度が数GHz=1秒間に大体10^9命令行えることから、競プロのC++では10^8くらいにオーダーを抑えると間に合って、10^7だと安全と言われています。
(O(2N)をO(N)のように定数倍を落として考える、ジャッジサーバーの処理時間、C++の1命令がCPUの1命令ではない…などの理由からO(10^9)のコードは1秒では動かないことが多いです)
そのため、10^5を20回=2*10^6はかなり安全なラインだと推測できます。
D – Sum of difference
D – Sum of difference (atcoder.jp)
数直線にAnをプロットした時の、各点の距離の和と言い換えられそうです。
また、各点の距離はどの順番から計算してもいいため、計算順序は好きに変えられます。(A1~ANの数字の位置を変えても答えは変わらない)
数直線にAnをプロットした時のことをもっと考えると
入力例1:3 5 1 2 の場合 xx__x__ (xが点を打った場所) - ----- ---- 1~5の距離は1~2の距離と2~5の距離の和になるため、この辺りを纏めると効率良さそう?
上記のように、重複している箇所が複数含まれています。
結論をいうと、Anをソートした時にA0-A1間の距離はA0からANの各距離、N個が重複します。
A1-A2間の距離は、A0-A1間の距離の個数N個からはみ出た1個が消え、A1からANの各距離、N-1個が増えます…。といったように、重複する距離の個数はO(1)で求めることが可能です。
#include<bits/stdc++.h>
#include<atcoder/all>
using namespace std;
using namespace atcoder;
int main(){
int N;
cin>>N;
long long A[N];
for(int i=0;i<N;i++){
cin>>A[i];
}
sort(A,A+N);
long long ans=0;
long long sum=0;
for(int i=1;i<N;i++){
sum+=(N-i)-(i-1);
ans+=(A[i]-A[i-1])*sum;
}
cout<<ans<<endl;
}
E – Throne
解説ACしました。
問題文を言い換えると、Na=S+Kb(a>0,b>0)を満たすような整数bの最小を求める問題と言えます。
上記式をmod Nの式、S+Kb=0 mod Nと考えます。(=は正確には三本線が正しいですが、変換に出ないので=を使っています…)
S+Kb=0 mod Nを解く
式を変形すると
Kb=-S mod N
b=-S*K^(-1) mod N
となります。K^(-1)はKの逆元でKと掛けると1になる数のことです。
modの式の場合、両方を割ることはNGです。(modでない式の場合、1/Kが逆元になる=1/Kを掛けると1になるため両辺をKで割れますが、modの式の場合、1/Kは逆元でない=1/Kを掛けても1にはならないため両辺をKで割っても、Kを消すことができません。)
Kの逆元が求まればbが判明しそうです。
逆元を考える
mod Nが素数である場合、フェルマーの小定理が使えます。
フェルマーの小定理はa^(p-1)=1 mod p (a,pは互いに素でpは素数)
というものです。ここからaを1つ外に出すと、a*a^(p-2)=1 mod pとなります。
逆元は掛けたら1になる数なので、a^(p-2)は逆元であると言えます。
mod Nが素数でない場合、上記定理は使えません。
この場合、拡張ユークリッドの互除法で解くことができます。
拡張ユークリッドの互除法はax+by=gcd(a,b)を解くものです。
x=K^(-1)とした場合、Kx=1 mod Nが逆元の定義の式になります。
これはKxをNyで割った際に1余ると同じ事のため、Kx+Ny=1と言い換えられ、拡張ユークリッドの互除法が適用できます。
拡張ユークリッドの互除法の式の右辺からgcd(K,N)=1でなければ求めたいものは求められません。求められない場合どうすればいいか?ということですが解なしです。つまり、逆元は存在しません。
逆元が存在しないということは元々の式に当てはまるxやyが存在しないということになり、”-1″を出力することが正解となります。
拡張ユークリッドの互除法のプログラムはネットにあるものをペタっと貼りましょう。
これでNが素数かどうかにかかわらず逆元が求められます。
(ちなみにですが、正確には逆元の最小を求める必要があります。modの逆元は複数個あります。拡張ユークリッドの互除法は素直に組めば答えが最小となるはずなので、今回はそこまで気にする必要はありません)
余談
フェルマーの小定理による逆元は頻出項目です。
mod 素数を取る問題で、計算式に割り算が出る場合になんかはフェルマーの小定理による変換を行います。
a/b mod c (cは素数でc,aは互いに素) ->a*b^(c-2) mod c
このときmodの値は大きい(10^9+7とか)の場合が多く、b^(c-2)を愚直にpowで計算するとTLEします。
繰り返し二乗法などの高速化アルゴリズムを使いましょう。
(雑に説明すると、2^10を計算する際、2*2=4(2^2),4*4=16(2^4),16*16=256(2^8)と計算結果を倍々していき、2^8*2^2=256*4=1024(2^10)と計算結果を掛け合わせて10乗をつくる方法です。倍々していくためO(log乗数)で計算できます。)
実装
・-S*K^(-1)が答え
・gcd(K,N)=1でなければ逆元がないため解なし
ということが分かりました。上記を実装すれば良さそう…ですが、テストケース4つ目の場合は注意です。
N=10000,S=6,K=14はgcd(K,N)!=1ですが、解は存在します。
というのもgcd(10000,6,14)=2であり、これらは2で割ることができます。
2で割るとN=5000,S=3,K=7となりgcd(K,N)=1となり割ったことで素となり解ありになります。
計算前にgcdで割って、なるたけ素にできるようにしましょう。
(Na=S+Kbの両辺をgcdで割る感じなので、a,bの答えもgcd割られた数になりますが破城はしません。小さくなる分には最小を求める問題なので問題なしです。)
#include<bits/stdc++.h>
#include<atcoder/all>
using namespace std;
using namespace atcoder;
long long gcd(long long a,long long b){
if(a<b) return gcd(b,a);
if(b==0) return a;
return gcd(b,a%b);
}
//https://qiita.com/drken/items/3b4fdf0a78e7a138cd9a#6-%E9%9B%A2%E6%95%A3%E5%AF%BE%E6%95%B0-log_a-b
long long modinv(long long a, long long m) {
long long b = m, u = 1, v = 0;
while (b) {
long long t = a / b;
a -= t * b; swap(a, b);
u -= t * v; swap(u, v);
}
u %= m;
if (u < 0) u += m;
return u;
}
int main(){
int T;
cin>>T;
while(T-->0){
long long N,S,K;
cin>>N>>S>>K;
long long g=gcd(N,gcd(S,K));
N/=g;
S/=g;
K/=g;
if(gcd(N,K)!=1) cout<<"-1"<<endl;
else{
long long m=modinv(K,N);
long long x=-S*m;
x%=N;
while(x<0) x+=N;
cout<<x%N<<endl;
}
}
}
「1000000007 で割ったあまり」の求め方を総特集! 〜 逆元から離散対数まで 〜 – Qiita
拡張ユークリッドの互除法はここからソースを借りています。(上記説明もここを参考にしました)
難しい…。これ高校レベルの数学超えてますよね…?
F – Rook on Grid
移動の仕方は横→縦、縦→横の2通りあります。
ややこしいのは、2通りで到着先に重複があり、カウントは重複を含めてはいけないことです。
入力例2を詳しく見てみます。
5 4 4 3 2 3 4 4 2 5 2 .x.. .x.. .x.x .... .... (xが障害物のあるところ) この場合を下から上になぞる様に見ていきます。(縦→横と動く場合を軸に考えます) 一番下→右に4つ伸ばせる 下から2番目→右に4つ伸ばせる 下から3番目→右に1つ伸ばせるが、左から3つ目は横→縦から伸ばせる) 下から4番目→右に1つ伸ばせるが、左から3つ目は横→縦から伸ばせる) 下から5番目→右に1つ伸ばせるが、左から3つ目は横→縦から伸ばせる)
下から4,5番目は左から4つ目が空いているのに、下から伸ばせません。
何故かということを考えると、既に下にブロックがあるからです。
上記から、下から上になぞる場合は下のことが言えそうです。
右に障害物がない→Wだけ伸ばせる 右に障害物がある→一番左の障害物まで伸ばせ、障害物より右は下にブロックがない横の位置から伸ばせる
障害物より右は下にブロックがないを単純に見ていこうとするとTLEです。
セグ木で障害物がある場合は0、ない場合は1と管理することで範囲内の障害物のない場所の個数をlog(W)で計算する。などして高速化しましょう。
#include<bits/stdc++.h>
#include<atcoder/all>
using namespace std;
using namespace atcoder;
//https://algo-logic.info/segment-tree/#toc_id_3_2
template <typename X>
struct SegTree {
using FX = function<X(X, X)>; // X•X -> X となる関数の型
int n;
FX fx;
const X ex;
vector<X> dat;
SegTree(int n_, FX fx_, X ex_) : n(), fx(fx_), ex(ex_), dat(n_ * 4, ex_) {
int x = 1;
while (n_ > x) {
x *= 2;
}
n = x;
}
void set(int i, X x) { dat[i + n - 1] = x; }
void build() {
for (int k = n - 2; k >= 0; k--) dat[k] = fx(dat[2 * k + 1], dat[2 * k + 2]);
}
void update(int i, X x) {
i += n - 1;
dat[i] = x;
while (i > 0) {
i = (i - 1) / 2; // parent
dat[i] = fx(dat[i * 2 + 1], dat[i * 2 + 2]);
}
}
X query(int a, int b) { return query_sub(a, b, 0, 0, n); }
X query_sub(int a, int b, int k, int l, int r) {
if (r <= a || b <= l) {
return ex;
} else if (a <= l && r <= b) {
return dat[k];
} else {
X vl = query_sub(a, b, k * 2 + 1, l, (l + r) / 2);
X vr = query_sub(a, b, k * 2 + 2, (l + r) / 2, r);
return fx(vl, vr);
}
}
};
int main(){
int H,W,K;
cin>>H>>W>>K;
auto fx = [](int x1, int x2) -> int { return x1+x2; };
int ex = 0;
SegTree<int> rmq(W, fx, ex);
for(int i=0;i<W;i++){
rmq.update(i,1);
}
int X[K],Y[K];
vector<int> v[H];
for(int i=0;i<K;i++){
cin>>Y[i]>>X[i];
X[i]--;
Y[i]--;
v[Y[i]].push_back(X[i]);
sort(v[Y[i]].begin(),v[Y[i]].end());
}
long long ans=0;
bool zf=false;
for(int i=0;i<H;i++){
if(v[i].size()!=0&&v[i][0]==0) zf=true;
if(zf){
//cout<<"0--"<<rmq.query(1,W)<<endl;
for(int j=0;j<v[i].size();j++){
//cout<<i<<"..."<<v[i][j]<<endl;
rmq.update(v[i][j],0);
}
ans+=rmq.query(1,W);
}
else if(v[i].size()==0){
//cout<<"1--"<<W<<endl;
ans+=W;
}
else{
for(int j=0;j<v[i].size();j++){
//cout<<i<<"..."<<v[i][j]<<endl;
rmq.update(v[i][j],0);
}
if(i==0){
for(int j=v[i][0];j<W;j++){
rmq.update(j,0);
}
}
//cout<<"2--"<<v[i][0]<<","<<rmq.query(v[i][0]+1,W)<<endl;
ans+=v[i][0]+rmq.query(v[i][0]+1,W);
}
}
cout<<ans<<endl;
}
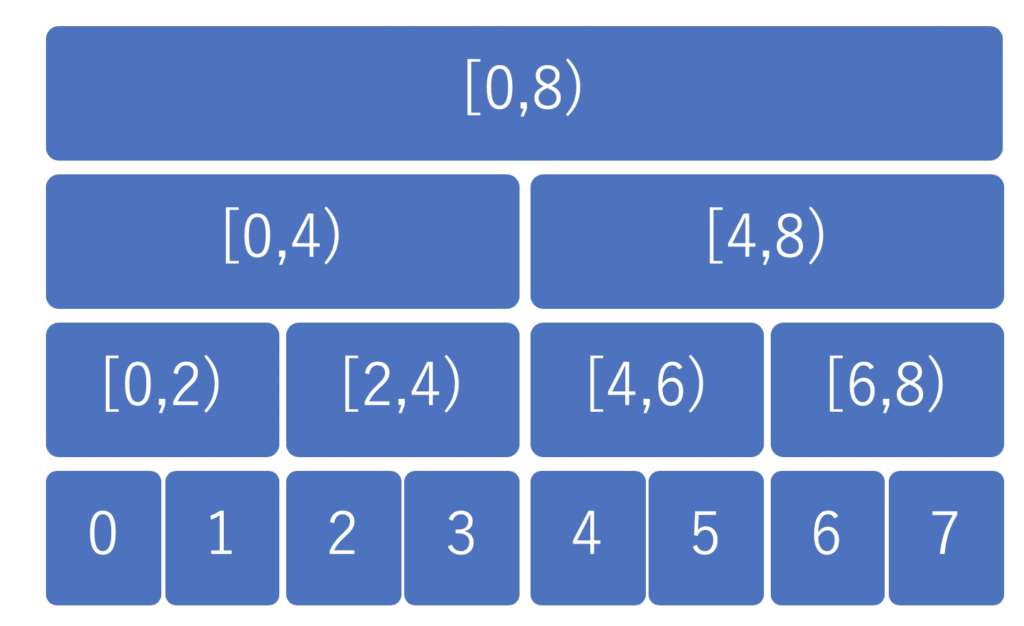
セグ木はここからお借りしました。
この問題、他に注意点として2つあります。
縦 H マス、横 W マスのグリッドがあります。上から i 行目、左から j 列目のマスをマス (i,j) と表します。 グリッド上には M 個の障害物があり、i 番目の障害物はマス (Xi,Yi)に置かれています。
と、何故か縦がXで横がYとなっており直感に反する入力となっています。
cin>>Y[i]>>X[i];
私は入力の際にXとYを逆転させてますが注意です。
もう1点は、(1,Y),(X,1)がある場合の処理です。
(1,Y)があればそれより上は右に行くルートがなくなります。(X,1)があればそれより右は上に行くルートがなくなります。この辺り、フラグ等で管理し丁寧に実装する必要があります。
おわりに
E問はmodのことを一通り復習出来て良かったです。
F問は解法はコンテスト中に分かったので解き切りたかったのですが…、実装力が足りませんでした。
今回、かなり知見が得られて良いコンテストでした。
数学の復習やライブラリの整備を正月に進めたいですね><


コメント